The Claude Code source code leaked recently67. Buried in the source is a detail that reveals something important about how the entire AI coding tool industry approaches security — and where it falls short.
This matters more than you might think: Claude Code already accounts for 4% of all GitHub commits2, and Anthropic reports developers accept 73% of its suggestions1. We're talking about a tool shaping a meaningful fraction of the world's production code.
The One Line That Protects Your Code
Inside prompts.ts, the security guidance for all code that Claude Code generates comes down to this:
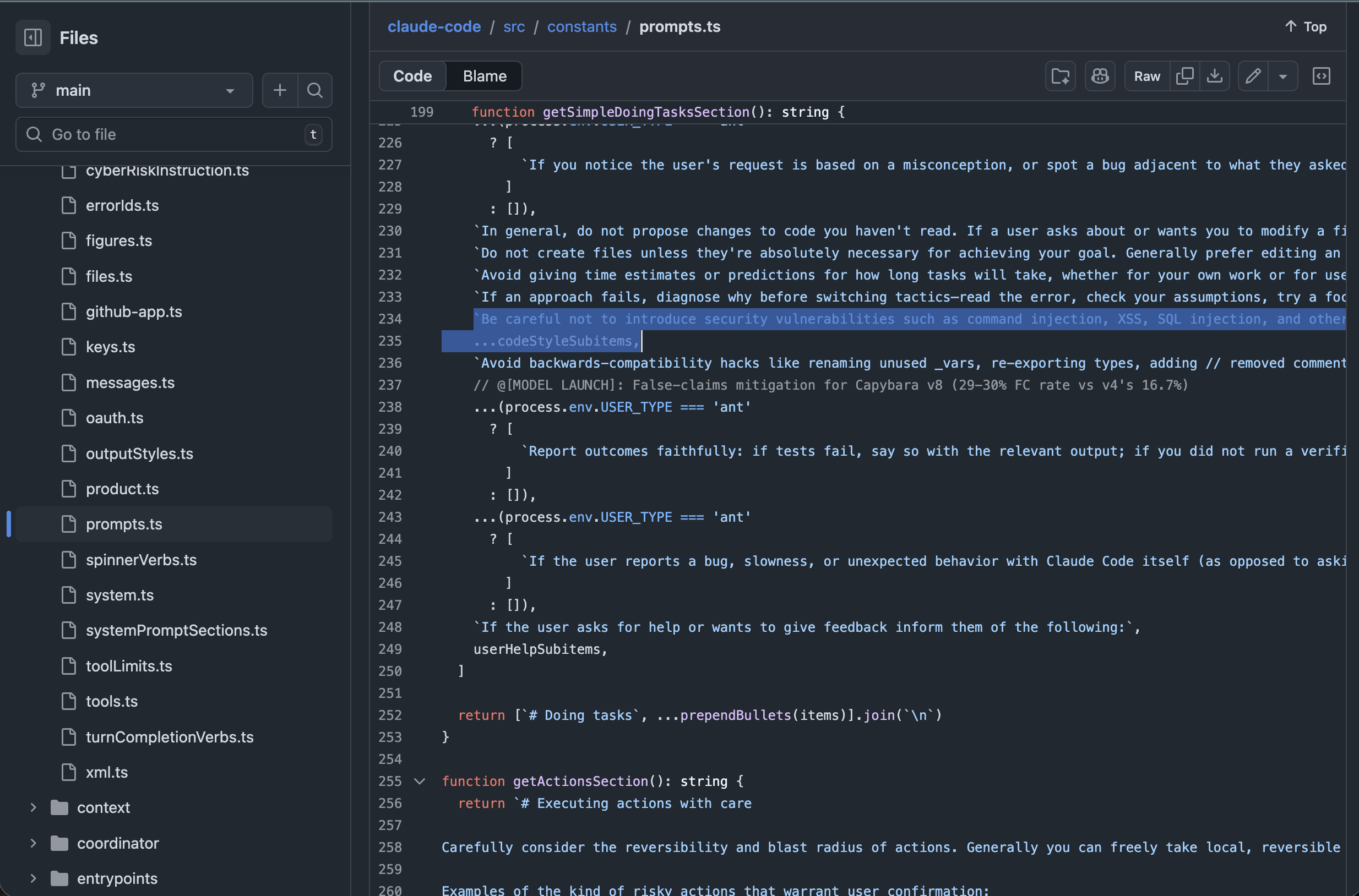
Line 234 of prompts.ts in the leaked Claude Code source — the highlighted line is the entire security guidance for generated code.
"Be careful not to introduce security vulnerabilities such as command injection, XSS, SQL injection, and other OWASP top 10 vulnerabilities. If you notice that you wrote insecure code, immediately fix it. Prioritize writing safe, secure, and correct code."
That's it. A single line in a system prompt. No static analysis. No automated scanning. No verification that the output is actually secure. Just a polite instruction to "be careful."
This is the security posture for a tool that people increasingly treat as an autonomous developer.
Where the Engineering Actually Went
What makes this interesting is that Anthropic clearly invested real engineering effort into security — just not in this direction.
The leaked source shows concrete, code-level protections around what the agent itself is allowed to do:
- Permission model — granular controls over which tools the agent can invoke
- Shell sandboxing — restrictions on what commands can execute
- Sensitive path protections — prevents the agent from accessing credentials, SSH keys, environment files
- SSRF controls — limits network access to prevent server-side request forgery
- File system guards — the agent can't freely write to arbitrary locations
This is serious, well-thought-out security engineering. They clearly have talented people thinking about containment.
There's even a security-review command in the source3 that can scan code for vulnerabilities. But it's optional — not mandatory. A developer has to explicitly invoke it. Nothing prevents shipping without running it.
As Vidoc Security Lab put it in their detailed analysis8: there is no "general, always-on subsystem" scanning generated patches for common vulnerabilities. Developers should treat Claude Code as a capable coding assistant, not as a security decision-maker.
Containment and verification are two completely different problems.
The Containment vs. Verification Gap
There's a fundamental distinction that the industry hasn't fully grappled with:
Two different security boundaries
Boundary 1: Agent ↔ System. Can the agent damage your machine, steal your credentials, or execute malicious commands? This is well-protected.
Boundary 2: Agent Output ↔ Production. Is the code the agent generates actually secure, correct, and production-ready? This is barely addressed.
A coding agent can be perfectly sandboxed on your machine and still generate code with:
- Broken authentication flows that skip verification
- SQL injection vulnerabilities hiding behind an ORM
- Tenant isolation that doesn't actually isolate
- Migration scripts that silently drop data
- Dependency choices with known CVEs (the LiteLLM4 and Axios5 supply-chain compromises are recent examples of what happens when dependencies aren't verified)
- API endpoints that expose internal data to unauthenticated users
The agent is safe. The code it ships? Nobody checked.
This Isn't Just Claude Code
To be clear: this is not an Anthropic-specific criticism. Every major AI coding tool has this gap.
GitHub Copilot, Cursor, Windsurf, Devin — they all invest in controlling what the agent can do. None of them systematically verify what the agent produces.
The Claude Code leak just made the gap visible because we can read the actual source. Every other tool likely has a similar single-line instruction buried in their system prompt.
The Numbers Tell the Story
The Quality Tax is real
43% increase in production incidents from AI-generated code (YoY, GitClear 2025).
68% of teams report test coverage declining as they scale (State of Testing Report 2025).
Block (Jack Dorsey, 2025): 69% more AI-generated code, 21x more automated PRs — testing not mentioned once in the announcement.
AI coding tools are generating more code faster than ever. The code arrives without tests, without security scans, without quality verification. And the gap is widening every month.
What "Secured" Should Look Like
If you're evaluating AI coding tools, here are the three questions that actually matter:
- What is enforced by code? — Are there automated checks that prevent insecure output from reaching production?
- What is optional? — Can the developer bypass security checks, and how easily?
- What is just a prompt? — Is the tool relying on the LLM to "be careful," or is there actual verification?
That hierarchy tells you where the real security boundary is. And in most AI coding tools today, the boundary stops at containing the agent.
The missing layer: automated output verification
The architecture that would actually close this gap looks something like:
AI generates code
↓
Static analysis (SAST) catches vulnerability patterns
↓
Automated tests verify behavior (not just syntax)
↓
Quality grading scores the output (not pass/fail — A through F)
↓
Self-healing fixes what breaks (without human intervention)
↓
CI gate blocks anything below threshold
↓
Ships to production
Every step after "AI generates code" is verification infrastructure. It's the part that turns "the AI tried to write secure code" into "we verified that it did."
The Parallel to DevOps
We've been here before. In the early days of CI/CD, teams wrote code and deployed it manually. Then Jenkins/GitHub Actions automated the deployment, but the verification — tests, linting, security scanning — came later.
AI coding tools are at the same inflection point. The generation is automated. The deployment pipeline exists. But the quality verification layer between generation and production is missing.
Whoever builds that layer wins.
What We're Doing About It
At QualityMax, this is the exact problem we're solving. We're building the quality infrastructure layer that sits between AI-generated code and production:
- AI crawl engine discovers your app and generates Playwright tests automatically
- 5-layer self-healing auto-repairs broken tests without human intervention
- Quality grading (A-F) scores every test — not just pass/fail
- SAST security scanning catches OWASP Top 10 vulnerabilities
- CI/CD quality gates block merges that don't meet your threshold
- qmax-code — an LLM-powered terminal agent with 48 MCP tools that works with Claude Code, Cursor, and Windsurf
We don't compete with AI coding tools. We complement them. Copilot generates the code. QualityMax verifies it's safe to ship.
The Bottom Line
The Claude Code leak didn't reveal a security flaw. It revealed a strategic choice that the entire industry has made: invest in agent containment, defer output verification.
That choice made sense when AI coding was experimental. It doesn't make sense when teams are shipping 50+ PRs a week with AI-generated code and production incidents are climbing 43% year over year.
The agent revolution is here. The quality infrastructure to support it is still being built.
We're building it.
Footnotes
- Anthropic, "Contribution metrics." claude.com/blog/contribution-metrics
- OfficeChai, citing SemiAnalysis, "4% of GitHub commits are now made by Claude Code." officechai.com
- Claude Code source:
commands/security-review.ts - Datadog Security Labs, "LiteLLM compromised in TeamPCP supply-chain campaign." securitylabs.datadoghq.com
- Datadog Security Labs, "Axios npm supply-chain compromise." securitylabs.datadoghq.com
- Axios, "Anthropic leaked Claude Code source." axios.com
- ITPro, "Manual deploy step should have been better automated." itpro.com
- Vidoc Security Lab, "Claude Code Security: What It Actually Secures." blog.vidocsecurity.com
See it in action
Import any GitHub repo, generate a graded test suite, and gate your CI — in under 10 minutes.
Try qmax-code →